Benchmarking zkVMs for Ethereum
Thanks to Marius van der Wijden, Jochem Brouwer, Ladislaus von Daniels, and Kevaundray Wedderburn for their feedback.
zkVMs unlock an efficiency shift for block execution: instead of every node re-running the same computation to verify a block, a single execution can produce a proof that anyone can quickly verify. This means blocks only need to be executed once, dramatically reducing redundant computation in the network — a step toward a more scalable and sustainable Ethereum.
The zkEVM team at the EF is working on many fronts to assess if zkVM technology is ready for Ethereum Mainnet use. The surface area is quite large, covering performance, security, EL compilation suitable for running in zkVMs, and CL adaptation requirements, among others.
Are zkVMs performant and reliable enough for L1 block proving? In this article, we explain how we are approaching this question by addressing worst-case blocks, building the proper tooling, and combining as many ELs and zkVMs as possible to collect measurements that map to potential protocol-level decisions.
Goal
The goal is to assess whether zkVMs are performant and reliable enough to achieve real-time proving (RTP), not only for average blocks but also for worst-case scenarios. Not achieving RTP puts the network's liveness and finality at risk, in the same way a mispriced opcode or precompile.
Any worst-case that makes RTP not achievable can have two leading causes:
- The underlying zkVMs are not optimized enough, but there are pending optimizations that might be able to close the gap.
- Or, there are protocol changes that are required, as no amount of engineering can fix the problem (e.g., blake2f precompile execution is order of magnitude more expensive to execute in a zkVM than in normal execution, thus mispriced for zkVMs, or unchunkified code can be a blocker after some particular gas limit).
This logic is analogous to analyzing if a particular precompile should be repriced or EL teams can optimize their implementation. Now, there’s a new dimension to consider, which is not only raw block execution, but block proving.
As with any benchmarking measurement, we need to define some constraints about what constitutes the most powerful acceptable hardware to claim RTP is possible. A recent article tentatively proposed goals for capex, opex, proof sizes, and generation latencies for RTP on Mainnet. These assumptions help to determine which hardware is suitable for use in measurements.
Benchmarking isn’t only about measuring, but also about quickly reacting to initial measurements and having a working cycle of optimizing and benchmarking again until diminishing returns are achieved (i.e., it doesn’t make sense to have conclusions in unoptimized opportunities).
The components involved in the benchmarking are:
- zkVMs: these are the machinery used for generating proofs.
- zkVM guest program: This is a technical term used to describe the program execution that is verified. In our case, the program is a particular EL stateless block execution logic. (e.g., Nethermind code method that receives the block and all required state, verifies the inputs are valid, and validates the block).
We’ll dive more into how these two fit together soon, so if this looks confusing, keep reading!
It is worth emphasizing that we are not interested in analyzing zkVMs in arbitrary guest programs. Many public claims about zkVM performance use programs like Fibonacci calculators or similar toy examples to prove throughput. While this is acceptable for other use cases, our team isn’t interested in these synthetic measurements; instead, we focus solely on Ethereum-specific goals. Benchmarking other guest programs is out of scope.
Why do we need a specialized approach?
Note: This section attempts to generalize concepts across various zkVMs, many of which incorporate numerous engineering optimizations, such as transpilation, parallelization, and pipelining. We adhere to general principles that apply to all zkVMs, with some degree of simplification.
To understand what we are measuring, it is useful to have at least a rough mental model of how things work in normal EL and zkVM execution. Let's unpack the layers involved in proving blocks. If we can identify these layers, we can better understand the nature of what we’re measuring, mainly regarding the correct fixtures to run.
Building the right mental models
If you are a core developer or node runner, your mental model of how your node runs can be roughly the following:
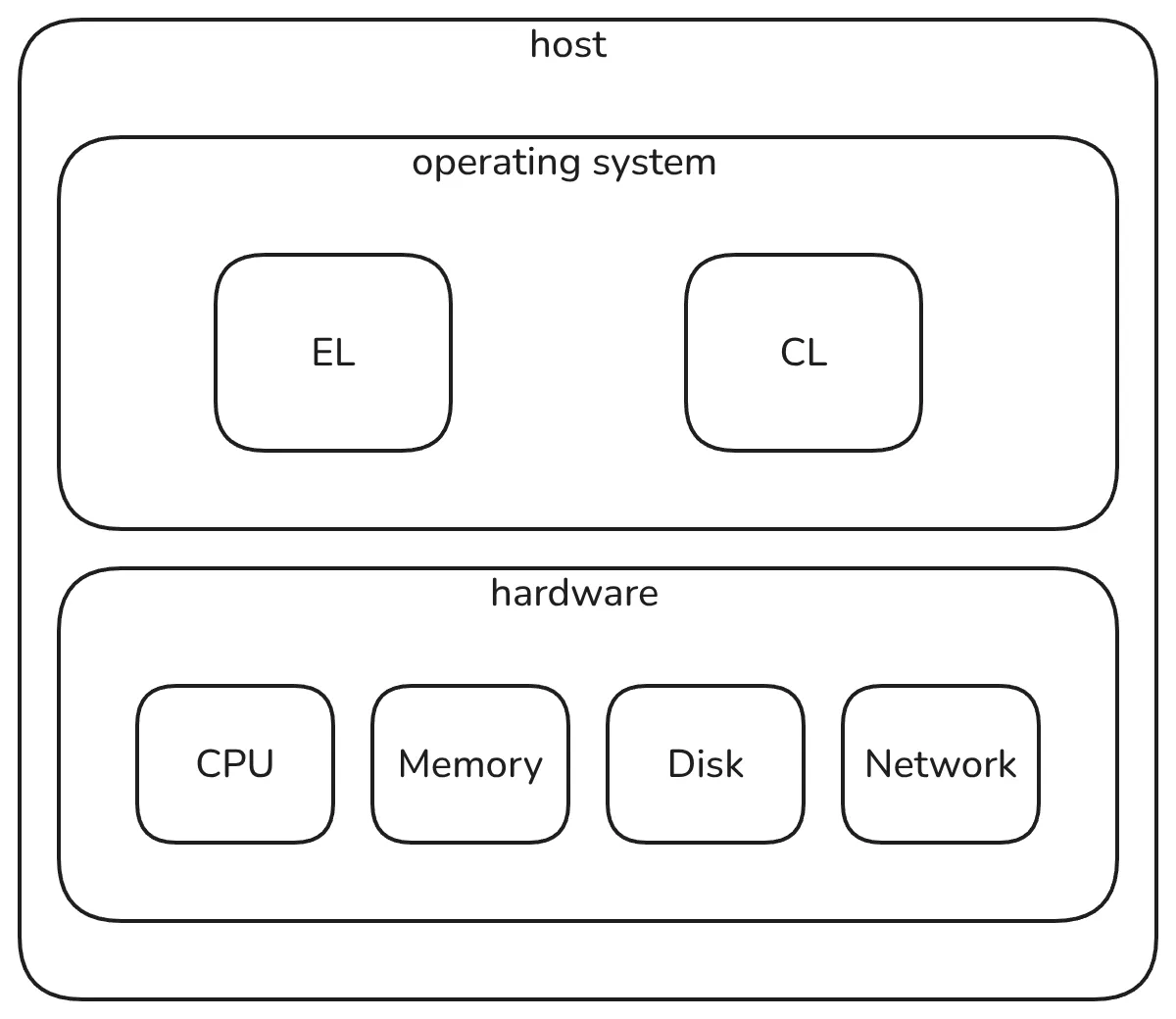
Notes:
- Your host machine has hardware such as CPU, memory, network, and disk.
- The host machine runs an operating system, such as Linux or Windows.
- You compile your preferred EL and CL clients targeting your machine architecture, e.g., amd64, ARM, etc.
- The operating system allows you to run these compiled programs, which connect to the Ethereum network, receive blocks, and re-execute them to validate their correctness (and potentially attest if you’re a validator).
- The block re-execution utilizes the hardware CPU, memory, and disk.
Note that this mental model applies equally to a local block builder and a block validator. More advanced block builders can have more involved architectures, but, generally speaking, they are conceptually similar.
In a zkVM proving world, the party generating the proof and verifying it looks quite different:
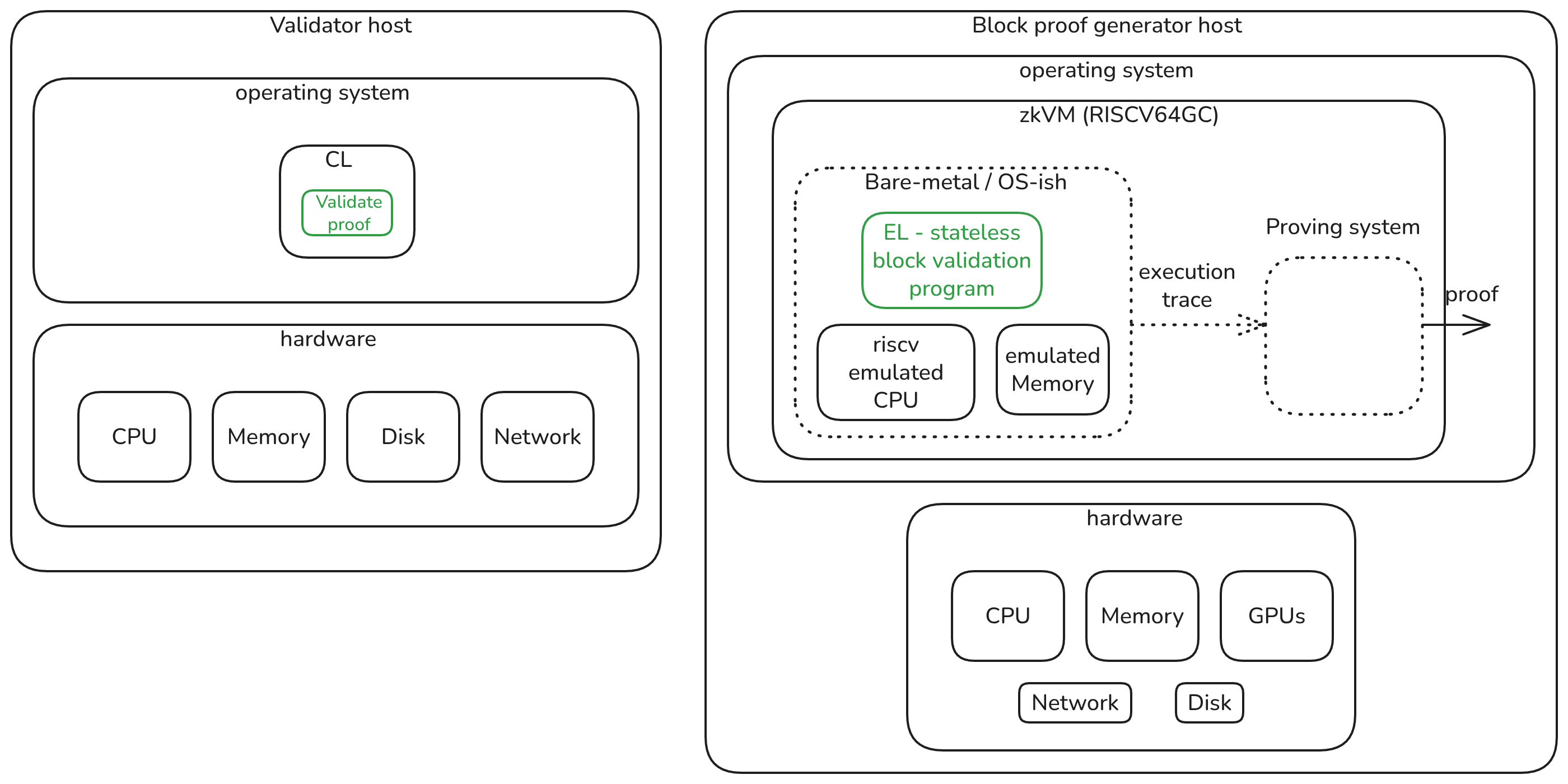
Note: the diagram shows a RISCV zkVM, but a zkVM targeting other ISAs, such as MIPS, should be the same.
Let’s unpack what is going on in the diagram:
- Validator host
- This diagram is identical to the one we showed earlier, except that it does not include the EL. A node that is verifying execution proofs doesn’t need to run a full EL node; thus, it has less CPU, memory, and (notably) no disk usage.
- The CL is still running, connected to the Ethereum network, and continues to receive blocks. Instead of calling the EL via the Engine API to request validation of a block, it directly verifies a cryptographic proof, which takes a couple of milliseconds. This smooths out the worse cases for the validator, but moves them onto the prover
- Block proof generator host
- The prover host machine still has raw hardware components and an operating system.
- It also runs a special set of programs which could be seen as a separate emulated machine (i.e., VM). Inside this VM, the guest program is run (i.e., a stateless block validation program we mentioned earlier). During this program execution, an execution trace is created, which is used by the zkVM proving system to generate the proof.
- The prover still requires a disk and network for basic functions, such as booting or returning the proof, but not for Ethereum-related tasks. To generate the proof, the prover is provided the block to be proven plus a witness which contains extra information to execute the block statelessly. This witness is not trusted e.g., it contains the state required to execute the block statelessly but it comes with an MPT that matches the parent block state root, thus the prover doesn’t have trust assumptions of who provided the inputs. Hence, there aren’t any new trust assumptions.
The primary target of the zkVM benchmarking efforts is this Block proof generator actor, as it is the most complex component compared to verifying a proof, which only requires a cryptographic library, utilizes commodity hardware, and, by design, always runs in the order of milliseconds.
Diving a bit more into their differences
Clearly, running a specific EL as a full node and as a guest program should share, say, 90% of the same codebase. This is the main benefit of trying to compile an existing EL to another ISA, i.e., instead of compiling to amd64/arm, compile to riscv64gc — if the original code is reused, we can leverage the lindy effects accumulated through time, having more confidence that we aren’t starting from scratch regarding protocol implementation bugs for most of the stateless block validation logic. The remaining 10% refers to special versions of internal components or new logic needed for stateless execution. Examples of these include a sparse MPT where not all nodes are known, validation of input data, and potential adjustments of some dependencies (usually cryptography-related).
Without getting into extreme detail, many fundamental engineering assumptions are different between normal block execution in hardware and inside a zkVM:
- An EL full node client compilation target is the host machine architecture (amd64/arm). This means that the ISA, compared to RISCV, has many more instructions that can change how optimized the compiled program is.
- An EL full node can leverage special instructions available in standard CPUs, such as AVX2 or AVX512, to optimize specific cases, including cryptography workloads. The zkVM machine doesn’t have these special instructions, since the target ISA don’t include them and usually the cryptography doesn’t have a way to speed them up.
- An EL full node runs under some defined constraints of available memory — not only in how much RAM is available, but also in how fast it is to access that memory. The zkVM machine's amount of memory does not equal the host memory; thus, the EL client has other assumptions regarding the total available memory (note that in the last diagram, “Emulated memory” isn’t the same as hardware “Memory”!). The amount of memory available depends on the zkVM.
- An EL full node client can make assumptions about faster memory available at the CPU level (e.g., L1, L2, L3 caches) and optimize its implementation accordingly. The zkVM emulated CPU doesn’t have these faster kinds of memory available, nor can it implement other features like prefetching or speculative execution.
- Regarding state access:
- An EL full node client architecture assumes that for the reading state, it should access a very slow medium, such as an SSD, and assumes this medium is trustworthy since it was self-built.
- A stateless EL block validation program doesn’t read the state from disk but from memory, since it is provided as input. Although this sounds convenient to avoid disk accesses, the provided data as input should be verified via an MPT proof, which is not present in the CPU load of the full node case. Also note that a “memory access” in a zkVM is an emulated operation, and it has different relative latency costs compared to other computational operations (i.e., the same as “memory access” inside an EVM vs. hardware memory access).
The above isn’t a comprehensive list, but hopefully it is enough to understand why benchmarking zkVMs for Ethereum is very important. Although 90% of EL client code is shared, the difference in execution environments results in varying relative costs between operations; therefore, we can’t extrapolate from raw block execution.
What doesn’t change is the fundamental approach to benchmarking in general:
- We need benchmark fixtures, which:
- Stress host hardware limits, as defined in the target capex; for example, we don’t have an infinite number of CPUs, GPUs, or memory.
- Stress zkVM emulated hardware limits. For example, how fast RISCV instructions are emulated, or how much zkVM memory is available.
- Stress the 10% of validation logic that differs between a full and a stateless block validator, as this differing logic is rarely accounted for in any normal full node benchmarking.
- We need tooling that simplifies executing the benchmarks under different zkVMs and ELs guest programs, in a way that is fair and easy to reproduce in all zkVMs.
Although many zkVMs have benchmarked block proving on their own, they have typically employed different guest programs and non-uniform fixtures to measure their performance (e.g., only Mainnet blocks, arbitrary gas limit blocks, and underlying workloads). This makes it extremely challenging to compare benchmarks, reproduce them, and ultimately draw any conclusions about whether protocol changes might be required.
Methodology
The plan that we’ve been executing involves three stages:
- Stage 1: Create benchmark cases
- Stage 2: Run benchmarks in all possible EL/zkVM combinations
- Stage 3: Analyze results
Although they are numbered incrementally, some stages can be worked in parallel. Also, many of the stages are frequently reiterated due to newly discovered cases to cover, optimizations done in EL guest programs, new faster releases in zkVMs, or better configurations of setups. Precisely the same as full node benchmarking, it is an ongoing process which hopefully converges to an optimal best case result.
Stage 1 - Create benchmark cases
While benchmarking Mainnet blocks is acceptable, relying solely on this approach is insufficient. In Ethereum, we’re not usually interested in the average case, but in worst cases, since those can be DoS vectors that can hurt the liveness or finality of the network (intentionally or unintentionally).
In May 2025, we began working on incorporating benchmark cases into EEST. After the effort started, many more core developers from different teams joined in, which improved the quality of cases, as many of them require experience in implementation details to create worst-case configurations (a reference to the PRs can be found here). We would like to specially thank the entire STEEL team for their support of this work.
The strategy for creating benchmark cases involves slicing different workloads that can occur during block executions. For example, creating blocks that use all the available gas limits for single opcodes (e.g., KECCAK, SSTORE, SLOAD, ADDMOD), precompiles (e.g., BLAKE2F, MODEXP, BLS12_G1MSM), or exploit more structural weaknesses (e.g., unchunkified code). This was done for all available opcodes, precompiles, and the most relevant protocol weaknesses. Note that even for single opcodes and precompiles, there are many cases covered (e.g., SSTORE/SLOAD have different cases for cold/hot storage, or precompiles depending on their inputs, which can be harder to execute). Additionally, the gas limit per block is configurable, allowing for the creation of designed worst-case scenarios for potential upcoming gas limits.
Another strategy for benchmarking instructions or precompiles is to isolate their work in a specific EVM implementation, such as REVM, since this can remove potential extra noise from measurements. This is an interesting strategy, but it also has downsides — REVM is not the only EVM implementation; thus, we would still have to run the benchmarks on all possible EVM implementations to obtain meaningful numbers for our conclusions. Relying on the EEST test framework already provides a standard and support interface where we can target all EL clients. Plus, the extra block overhead isn’t that meaningful for any reasonable block gas limit, e.g., if in a block you execute CPU only opcodes/precompiles, there’s no meaningful workload of state root calculations, meaningful system contracts work, or meaningful transaction tries root load — and for stateful opcodes (e.g. SSTORE/SLOAD), you actually do want to execute in a block context, because post state root calculations and similars are very relevant side effects. There can also be other strategies to measure the marginal overload between two blocks with only a delta execution of the target opcodes/precompile.
These fixtures are not only valid for zkVM benchmarking, but also for full node executions. In fact, the Perfnet and Bloatnet efforts have begun collaborating with us on the EEST benchmarks to create a corpus of tests that can be utilized by various initiatives within the Ethereum ecosystem.
For zkEVM benchmarking purposes, having these fixtures is extremely useful. We can identify mismatches between the expected cost/effort (i.e., gas used) for all opcodes and precompiles versus their actual proving times. The way a new opcode/precompile target is priced by comparing it relatively with other already priced opcodes/precompiles. This allows us to assign the correct relative effort so the desired bound on resources is enforced.
This is where our mental model comparison in the previous section should come in. The execution environment for a block validation in a normal EL client vs. in a zkEVM is quite different. Relative costs between opcodes and precompiles will be different from those in direct hardware execution; thus, we can expect potentially significant mismatches. This doesn’t mean that the gas pricing should be perfect for one environment or the other, but it is helpful to adjust it enough so pathological cases don’t become blockers for using this technology if it is valuable for the protocol.
Known workloads that are challenging for zkVMs compared to raw execution are:
- Hashing operations, since bitwise operations are optimized in hardware CPU, but can be challenging for zkVMs proving systems (i.e., they use non-power-of-2 prime finite fields for handling data, and not bits).
- Other cryptography-related opcodes/precompiles, since low-level cryptography libraries are usually optimized for other ISAs, and/or it won’t be a good fit for the proving system.
Today, zkVMs target the most challenging cases with a concept of “zkVM precompiles” (see here and here). These are patched implementations that have a high-level implementation that is more friendly to the zkVM design, or directly provide those as native operations (i.e., syscalls).
Stage 2 - Run benchmarks in all possible EL/zkVM combinations
After we have the EEST test cases, we need tooling to generate proofs for these blocks under different configurations with the following dimensions:
- EL used as the guest program.
- zkVM that will be creating the proof.
- Underlying hardware configuration (which CPU, GPU(s), etc).
Testing on different combinations is important for the same reasons we value client diversity in the protocol. The more combinations we can run on Mainnet, the less chance there is of correlated failures that can cause a liveness failure in the network.
The number of full combinations is similar to the EL/CL matching performed for testing — instead of matching ELs with CLs, it would be with zkVMs for block proving.
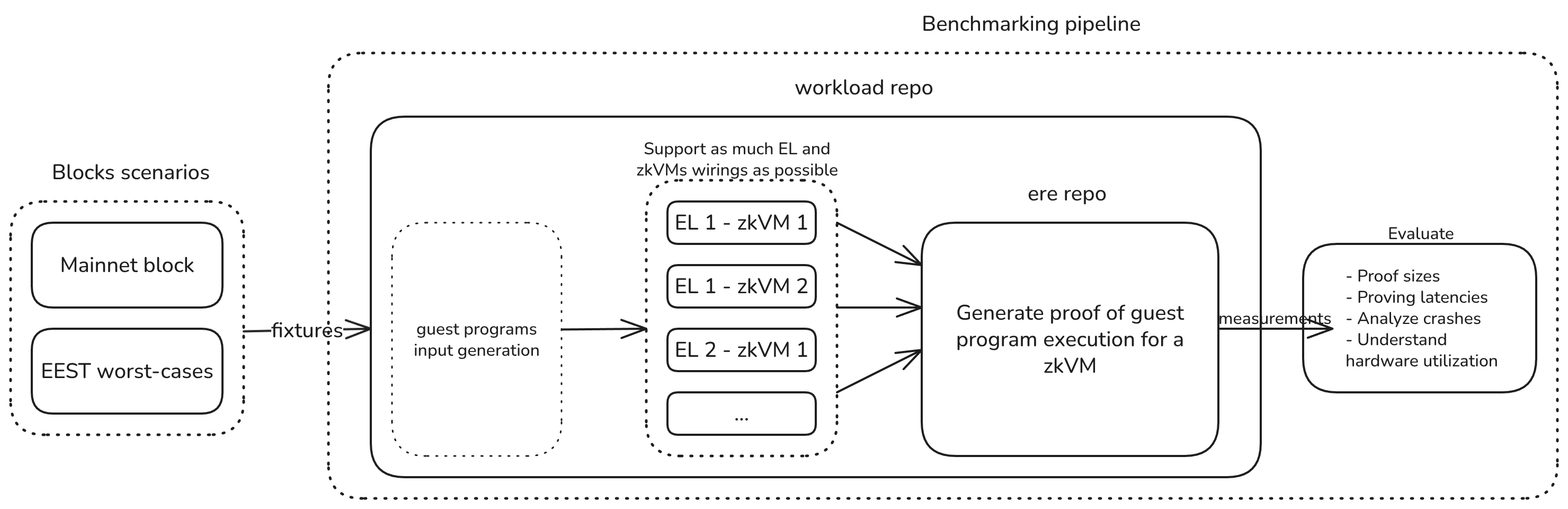
To do this, our team has been working on two main repositories:
- ere: a library that abstracts many zkVMs under a unified interface so users can simplify the process of compiling guest programs, creating proofs, and verifying them. Regarding compilation, although the repository is written in Rust, its goal is to compile non-Rust ELs as well.
- workload: uses ere to benchmark proof generation for Mainnet or any EEST test/benchmark artifact, for as many ELs and zkVM pairs we can integrate.
With these tools, it is easier to have reproducible runs on different hardware, check the readiness of various zkVMs and EL combinations, determine the severity of worst-case blocks, and potentially identify EL optimizations for them, among other benefits.
Tentative results for proving are uploaded to this public repository. As time passes, we’ll continue to add updated and new run combinations — so expect more changes on this front.
Stage 3 - Analyze results
The main strategy to onboard zkVMs into Mainnet is to provide multiple combinations of EL/zkVMs proofs to ensure that bugs in any EL or zkVM don’t harm network liveness or finality. The exact mechanism by which this works is still under research, and we plan to write a dedicated article on this topic in the near future.
This means that we need to have integrated and measured the performance of as many EL/zkVM combinations as possible to understand which one has the worst-case performance among these combinations.
After we have this information, we can at least conclude two main things:
- The P99 threshold for RTP latency numbers is satisfied for a long history of Ethereum blocks.
- Identified worst-case block cases designed in EEST with the current protocol specs (e.g., pricings) do not become DoS vectors — assuming no other new incentive is designed to avoid this risk.
We can get a high-level picture of how all of these parts fits together in the following diagram:
Final words
Hopefully, after reading this article, you can have a better mental model of how zkVMs are used to generate proofs and how they compare to raw EL client execution. Our work complements Ethproofs, as we’re not interested in measuring only average blocks (Ethproofs' primary focus), but rather worst-case ones, which can serve as potential attack vectors, in order to continue making Ethereum the safest and most reliable network.
You are invited to track our ongoing work to help us improve our tooling. Today, in ere we have support for eight zkVMs with different levels of maturity. Each of them is tracked on new SDK releases and internal workings, allowing us to provide the most performant unified integration. In workload, we already support Mainnet and EEST benchmarks, combining two EL clients with multiple zkVMs. Our main goal is to integrate more ELs and zkVMs combinations, allowing each to be benchmarked under the same fixtures and hardware, thereby gaining a deeper understanding.
Over the last few months, we have collaborated with the Reth team and other zkVM engineers to identify the best ideas for optimizing ELs for zkVMs. The goal is not only to optimize a single client, but to learn the good ideas that will apply to all the upcoming ones. We have already shared the lessons we've learned from Reth optimizations with the Ethrex team, and we’re excited to continue helping more ELs apply these ideas.
As many core developers and zkVM teams continue to collaborate on optimizing ELs and zkVMs, the benchmarking tools we have created should enable us to repeat measurements quickly, allowing us to have a tighter feedback loop towards achieving our goal. We also need help in identifying new relevant worst test cases, so help in improving EEST benchmarks is greatly appreciated!